Referensi : https://www.megabagus.id/mendeteksi-kanker-payudara-dengan-machine-learning
Mendeteksi Kanker Menggunakan Algoritma Support Vector Machine (SVM)
Support vector machine (SVM) merupakan suatu teknik yang digunakan untuk prediksi, baik dalam kasus klasifikasi maupun regresi. Secara sederhana konsep SVM yaitu usaha untuk mencari hyperplane terbaik yang digunakan sebagai pemisah dua buah kelas pada input space. Hyperplane terbaik merupakan suatu garis yang memisahkan kelas data yang memiliki margin terbesar. Margin adalah jarak antara hyperplane tersebut dengan data terdekat dari masing-masing kelas. Data yang paling dekat ini disebut support vector.


Untuk menghitung nilai margin antara bidang pembatas menggunakan rumus jarak garis ke titik pusat dinotasikan sebagai berikut:
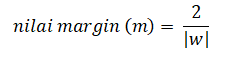
Fungsi ini biasanya digunakan untuk data yang sudah valid (available) dan merupakan default tools dalam SVM. Persamaan fungsi kernel RGF dapat dinotasikan dengan:

Biasanya digunakan untuk klasifikasi gambar. Persamaan kernel polynomial seperti berikut:

Fungsi ini sering digunakan untuk neural networks. Berikut persamaannya.
4. Kernel Linear
Merupakan fungsi kernel yang paling sederhana. Biasanya digunakan untuk klasifikasi teks. Persamaan fungsinya yaitu:
Data Set Characteristics: | Multivariate | Number of Instances: | 569 | Area: | Life |
Attribute Characteristics: |
Real |
Number of Attributes: |
32 |
Date Donated |
1995-11-01 |
Associated Tasks: | Classification | Missing Values? | No | Number of Web Hits: | 1643233 |
import pandas as pd
import seaborn as sns
sns.set()
# Mengimpor dataset
from sklearn.datasets import load_breast_cancer
kanker = load_breast_cancer()
# Menggabungkan ke dalam satu data frame
df_kanker = pd.DataFrame(kanker['data'], columns = kanker['feature_names'])
df_kanker['status'] = kanker['target']
# Visualisasi data
sns.pairplot(df_kanker, vars = ['mean radius', 'mean texture', 'mean area', 'mean perimeter', 'mean smoothness'], hue = 'status' )
# Plot korelasi dengan heatmap
sns.heatmap(df_kanker[['mean radius', 'mean texture', 'concavity error', 'mean area','mean smoothness']].corr(), annot=True, cmap='bwr')
# Persiapan training dataset
X = df_kanker.drop(['status'],axis=1)
y = df_kanker['status']
# Membagi dataset ke training set dan test set
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.2, random_state=0)
# Feature Scaling
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)
# Proses training dengan SVM
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
classifier = SVC(kernel='rbf', random_state=0)
classifier.fit(X_train, y_train)
# Mengevauasi model
y_predict = classifier.predict(X_test)
cm = confusion_matrix(y_test, y_predict)
sns.heatmap(cm, annot=True)
print(classification_report(y_test,y_predict))
Keterangan:
- Line 2-3 mengimpor library Pandas dan Seaborn untuk nanti digunakan.
- Line 4 mengaktifkan Seaborn.
- Line 7 mengimpor data set kita dari library sklearn.
- Line 8 mendefinisikan objek dengan nama kanker sebagai dataset yang nanti akan kita gunakan.
Berikut adalah tampilan data set kita secara umum yang berupa dictionary:


- Line 11 membuat objek baru (df_kanker) dengan tipe Data Frame agar lebih mudah dianalisis. Kita mengambil key data di dictionary kanker, kemudian kolomnya kita beri nama sesuai nama key feature_names.
Jika sudah dieksekusi, filenya akan tampak seperti ini di variable explorer:

Tampilan df_kanker di Spyder
Kalau dilihat objek df_kanker, maka kita belum memiliki variabel dependen-nya, yaitu status apakah kankernya malignant (0) atau tidak (1). Untuk bisa menambahkan variabel dependen ini, kita tambahkan kolom bari di line 12.
- Line 12, menambahkan kolom baru dengan nama kolom ‘status’ yang iambil dari key target dari dictionary kanker. Sekarang jika dicek di shape (size di variable explorer), maka kita memiliki total kolom sebanyak 31 kolom.
- Line
15 membuat pairplot. Kita ingin mendapatkan gambaran hubungan antara
beberapa kolom. Tentunya mustahil kita memasukkan semua kolom karena
terlalu banyak dan justru akan membuat bingung. Kita hanya memasukkan
beberapa kolom saja seperti mean_radius, mean_texture, dan lain-lain
(tentu saja pembaca bisa menggunakan kolom lain sebagai variabel
pairplot). Kita gunakan kolom status sebagai pembeda warna. Tampilannya
seperti berikut:


Kita bisa melihat bahwa warna merah tua menunjukkan bahwa hubungan antar dua variabel semakin menunjukkan korelasi positif. Artinya jika satu data naik, maka data satunya lagi ikut naik. Sementara warna biru tua menunjukkan hubungan korelasi negatif. Artinya jika satu data naik, maka data satunya lagi justru turun, dan begitu sebaliknya.
Line 42 membuat confusion matrix, dan line 43 membuat versi heatmap-nya. Tampilannya adalah sebagai berikut

Tampilan confusion matrix
Bisa dilihat bahwa hasil prediksi modle kita sangat baik. Dari kanker malignant (0), model kita bisa memprediksi dengan baik semua kanker ganas ini sebanyak 45 kali. Sementara model kita salah mendeteksi (false negative) sebanyak 2 kali (seharusnya benign (1), tapi dideteksi sebagai malignant (0)). Label bawah adalah kondisi sebenarnya, sementara label samping kiri adalah hasil prediksi model. Kemudian untuk kondisi malignant (0), model kita tidak melakukan false positive (seharusnya negatif tapi justru diprediksi positif), dan berhasil mendeteksi positif dengan benar sebanyak 67 kali.

Versi heatmap dari confusion matrix
Bisa dikatakan bahwa model kita memiliki akurasi sebanyak 98%. Ringkasannya bisa dilihat di ine selanjutnya.
- Line 43 kita membuat ringkasannya dengan menggunakan fungsi classification_report. Tampilannya sebagai berikut:

Tampilan classification report
Setelah melihat hasil ringkasan di atas bisa dikatakan bahwa performa model sangatlah baik, dengan akurasi sebanyak 98%.
Video

Tidak ada komentar:
Posting Komentar